Overview
Curious Dr. MISFA algorithm actively learns multiple slow feature abstractions in the order from least to most costly, as predicted by the theory of artificial curiosity. Each abstraction learned encodes some previously unknown regularity in the input observations, which forms a basis for acquiring new skills. Continual Curiosity-Driven Skill Acquisition (CCSA) framework translates the abstraction learning problem of Curious Dr. MISFA to a continual skill acquisition problem. Using CCSA, a humanoid robot driven purely by its intrinsic motivation can continually acquire a repertoire of skills that map the many raw-pixels of image streams to action-sequences.
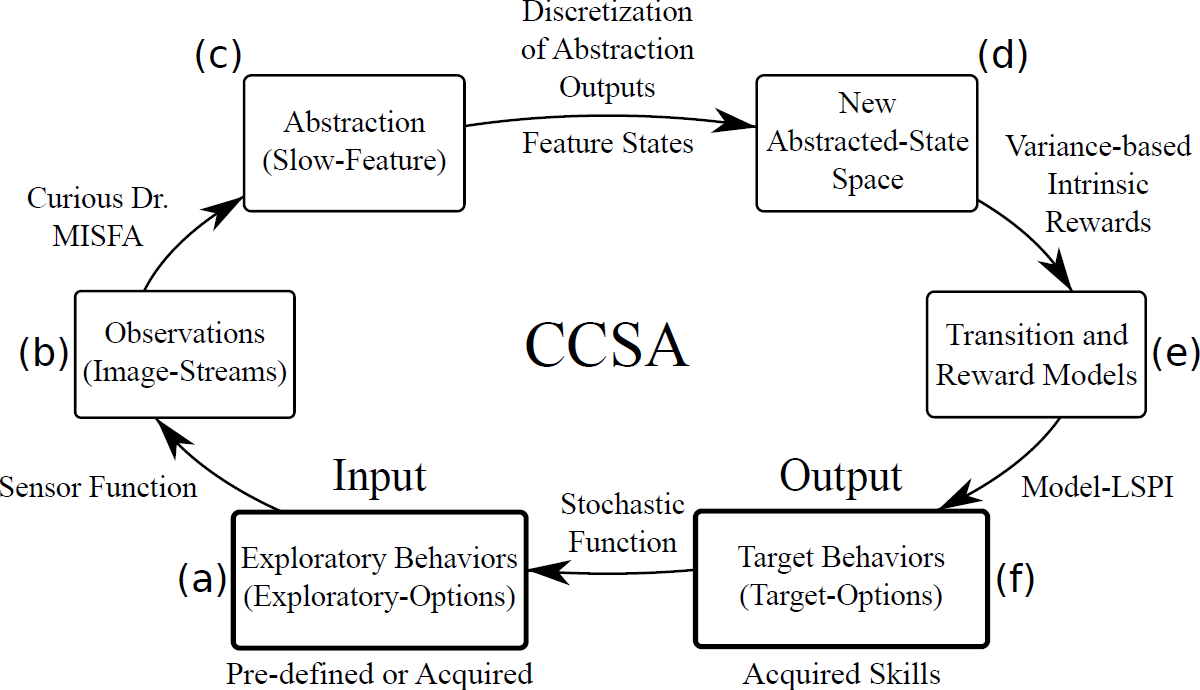
Figure 7 illustrates the overall CCSA framework. The learning problem associated with CCSA can be described as follows. From a set of pre-defined or previously acquired input exploratory behaviors that generate potentially high-dimensional time-varying observation streams, the objective of the agent is to (a) acquire an easily learnable yet unknown target behavior and (b) re-use the target behavior to acquire more complex target behaviors. The target behaviors represent the skills acquired by the agent. A sample run of the CCSA framework to acquire a skill:
- The agent starts with a set of pre-defined or previously acquired
exploratory behaviors. I make use of the options framework to
formally represent the exploratory behaviors as exploratory options. Each
exploratory option is defined as a tuple $\langle \mathcal{I}^e_i, \beta^e_i, \pi^e_i
\rangle$, where $\mathcal{I}^e_i$ is the initiation set
comprising states where the option is available, $\beta^e_i$ is the option
termination condition, which will determine where the option terminates
(e.g., some probability in each state), and $\pi^e_i$ is a pre-defined stochastic policy.
The simplest exploratory option policy is a random walk. However, I use a more sophisticated variant uses a form of initial artificial curiosity, derived from error-based rewards. This exploratory-option's policy $\pi^e$ is determined by the predictability of the observations ${\bf x}(t)$, but can also switch to a random walk when the environment is too unpredictable. - The agent makes high-dimensional observations through a sensor-function, such as a camera, upon actively executing the exploratory options.
- Using the Curious Dr. MISFA algorithm, the agent learns a slow feature abstraction that encodes the easiest to learn yet unknown regularity in the input observation streams.
- The slow feature abstraction outputs are clustered to create feature states that are augmented to the agent's abstracted state space, which contains previously encoded feature states.
- A Markovian transition model is learned by exploring the new abstracted state space. The reward function is also learned through exploration, with the agent being intrinsically rewarded for making state transitions that produce a large variation (high statistical variance) in slow feature outputs. This specialized reward function is used to learn action-sequences (policy) that drives the agent to states where such transitions will occur.
- Once the transition and reward functions are learned, a deterministic policy is learned via model-based Least-Squares Policy Iteration . The learned policy and the learned slow feature abstraction together constitute a target option, which represents the acquired skill.
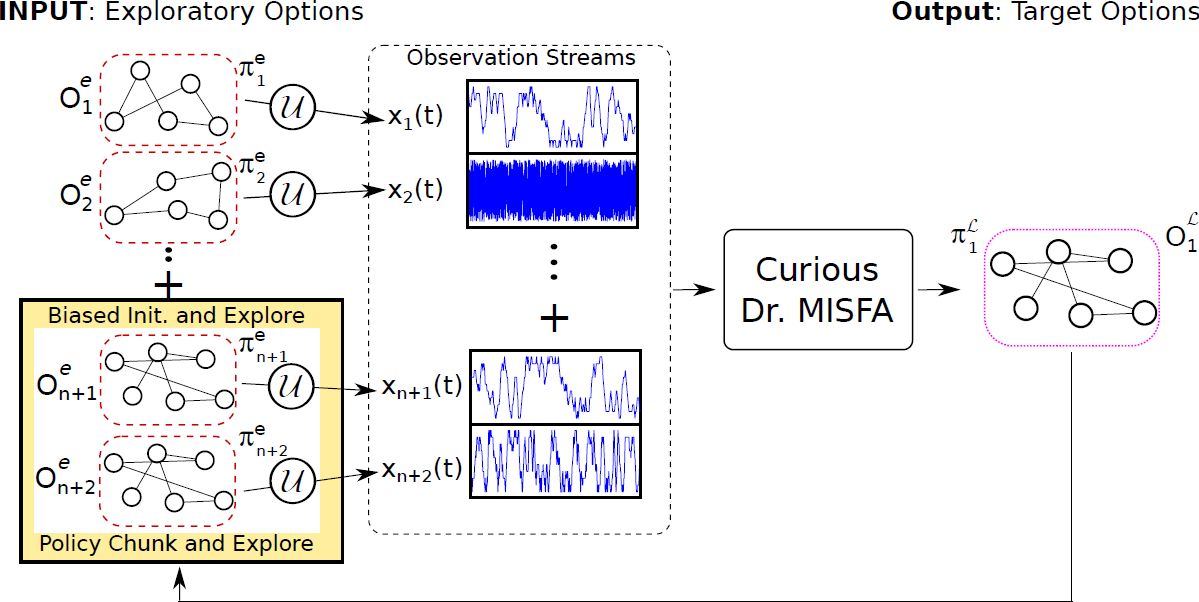
- The deterministic target-option's policy is modified to a stochastic policy in the agent's new abstracted states. This is done by constructing two new exploratory options that are based on the target option that was learned last. The first option, called the biased initialization and explore, biases the agent to explore first the state-action tuples where it had previously received maximum intrinsic rewards. Whereas the second option, called the policy chunk and explore, executes the deterministic target-option's policy before exploration. For each target option learned, these two exploratory options are added to the input exploratory-option set (Figure 8). In this way, the agent continues the process of curiosity-based skill acquisition by exploring among the new exploratory option set to discover unknown regularities. A complex skill can be learned as a consequence of chaining multiple skills that were learned earlier.
CCSA is a task-independent algorithm, i.e., it does not require any design modifications when the environment is changed. However, CCSA makes the following assumptions: (a) The agent's default abstracted state space contains low-level kinematic joint poses of the robot learned offline using Task Relevant Roadmaps. This is done to limit the iCub's exploration of its arm to a plane parallel to the table. This assumption can be relaxed resulting in a larger space of arm exploration of the iCub, and the skills thus developed may be different. (b) CCSA requires at least one input exploratory option. To minimize human inputs into the system, in the experiments at $t=0$, the agent starts with only a single input exploratory option, which is a random-walk in the default abstracted state space. However, environment or domain specific information can be used to design several input exploratory options in order to shape the resulting skills. For example, random-walk policies mapped to different sub-regions in the robot's joint space can be used.
Videos

Click to open the YouTube video.